ICCV 2017 · 论文精读答辩
Pixel Recursive
Super Resolution
像素递归超分辨率 · 给“马赛克”般的超低清图脳补出清晰细节
Ryan Dahl · Mohammad Norouzi · Jonathon Shlens
Google Brain
FUN FACT
第一作者 Ryan Dahl 正是 Node.js / Deno 的作者
背景 · 多模态难题
方法 · 条件网络 + 先验网络
实验 · 人类感知评估
CORE TASK · 巨幅放大
8×8 → 32×32
边长放大 4×,像素增至 16 倍 — 细节已不存在,必须凭先验“画”出来
CORE INSIGHT · 关键洞察
逐像素递归采样 替代 回归平均
超分是多模态问题;MSE 把所有可能糊成一团,自回归则每次给出一个清晰答案
RESULT · 人类感知评估
27.9%
生成图被判为真
(50% = 完全混淆)
(50% = 完全混淆)
CelebA:本文 11.0% vs. GAN 8.5%;LSUN:本文最高 27.9%
PART 01 / 04
研究背景
高倍超分为什么这么难 · 一张小图对应无数张大图
通俗讲,这就是「去马赛克」:把 8×8 人脸放大到 32×32。低倍放大已成熟,难点在极小输入 + 极大放大比。
输入
8 × 8 px
头发、皮肤纹理等细节已彻底丢失
输出
32 × 32 px
模型须凭先验合成出全新的真实细节
关键认知:模型并非「恢复」原始信息,而是像你画我猜—— 先猜「这是一张脸」,再凭经验把五官想象着画出来。本质是合理的脳补,而非还原真相。
Figure 1 · CelebA 人脸 · 8×8 输入 / 模型采样 / 真实图(最下排原图的嘴型、眼妆已与采样不同)

把研究背景浓缩成一条上升的主线:先看问题为什么难,再看老办法为什么糊,最后引出本文怎么解。
越往右上:从「恢复唯一真相」走向「建模条件分布,采样一个清晰、可信的答案」;台阶 3 自然过渡到方法部分。
高倍放大时,许多细节在输入里根本不存在。任务从「恢复」变成合成可信细节:一张小图对应无数张大图。
8×8 马赛克输入
可能 A
浓眉 · 直发 · 偏瘦脸型
可能 B
淡眉 · 卷发 · 圆润脸型
可能 C
不同肤质 · 不同光照
↑ 三张高清结果降采样回去都得到同一张马赛克 —— 它们同样「正确」,构成多个分立的解(多模态)。
结论:好的超分模型必须能对多种可能性建模、每次给出清晰的一个,而不是把它们平均成一团模糊。
超分看着像个「确定」的任务,本文却把它当概率问题来做。这一步抽象是全文的地基 —— 想通了,后面都顺。
① 经典视角:一张图 → 一张图
传统超分想学一个函数 $f$:输入低清 $x$,输出唯一高清 $f(x)=y$。低倍放大够用。
② 高倍超分是「一对多」
无数张不同高清图,降采样后都等于同一张 $x$,它们都对。一个只能吐一张图的函数,天生表达不了「多个都对的答案」。
③ 换对象:在「所有可能图像」上放一条分布
不预测一张图,而是给出概率分布 $p(y\mid x)$:在所有可能高清图里,哪些可信(概率高)、哪些不可能(≈0)。右图就是这条分布。
④ 抽象成分布后,三件事就顺了
① 能容纳多个答案;② 能从分布里采样出清晰的一张;③ 能用似然客观比较模型。这正是本文选 PixelCNN 的理由。
记住这步:超分的输出从「一张图」升级成「一整条分布」。下一页再看:这条分布长什么样,以及偷懒只取它的均值会怎样。
交互 · p(y|x):拖探针读「概率 / 似然」,调温度 τ,采样
温度 τ
1.00 · 标准
相对可信度 100%
概率 探针高度 = 这张图的概率密度;看整条曲线比「哪张更可能」。
似然 把探针停在真实图上,这个高度就是「模型给真实数据打的分」;训练 = 最大化它。
上一页把超分变成了一条分布 $p(y\mid x)$。现在只盯两件事:这条分布的「形状」,以及一个偷懒做法会出什么问题。
1
这条分布通常是多峰的
「数字放左上」和「放右下」是两个都对、却彼此分开的答案,就是两座山峰(见右图上半)。
2
可如果硬让它「只吐一张图」?—— 它只能吐均值
用 MSE 训练时,最优答案是所有可能图的平均 $\mathbb{E}[y\mid x]$。两座山峰一平均,正好落在中间山谷 —— 一张谁都不像的糊图(右图下半)。
关键结论:「糊」不怪网络不够强,而是「只输出一个均值」这件事本身的错。根因 = 把像素当独立;出路 = 链式法则。下一页把这两点算成公式 ⤵
同一个故事的「分布」视角
上一页是直觉,这一页是证明:A 解释「为什么平均 = 糊」,B 解释「为什么自回归能救回来」。这两点想通,§3 / §4 就全通了。
推导 A · 高斯 = MSE = 条件均值
① 假设每个像素服从固定方差高斯:
$$p(y_i\mid x)=\mathcal{N}\!\big(y_i;\,C_i(x),\,\sigma^2\big)$$
② 取对数(论文式 3):
$$\log p(y_i\mid x)=-\tfrac{1}{2\sigma^2}\big\lVert y_i-C_i(x)\big\rVert^2-\log\sqrt{2\pi\sigma^2}$$
③ $\sigma$ 固定 ⇒ 末项是常数 ⇒ 最大似然 = 最小平方误差:
$$\max\ \log p\ \Longleftrightarrow\ \min\ \big\lVert y_i-C_i(x)\big\rVert^2\ (\text{MSE})$$
④ 而使 MSE 最小的最优预测,正是条件均值:
$$\arg\min_{c}\ \mathbb{E}\big[\lVert y_i-c\rVert^2\mid x\big]=\mathbb{E}[y_i\mid x]$$
⇒ 选 L2 / MSE = 假设单峰高斯、只会预测条件均值;多峰被平均 → 糊。
推导 B · 链式法则:精确拆成逐像素
① 概率链式法则(恒等式,对任意分布都成立):
$$p(y\mid x)=\prod_{i=1}^{M} p(y_i\mid x,\,y_{\lt i})$$
展开即 $p(y_1\mid x)\,p(y_2\mid x,y_1)\,p(y_3\mid x,y_1,y_2)\cdots$
② 取对数(论文式 5):
$$\log p(y\mid x)=\sum_{i}\log p(y_i\mid x,\,y_{\lt i})$$
③ 对比「像素独立」假设(式 2)—— 少了 $y_{\lt i}$:
$$\log p(y\mid x)=\sum_{i}\log p(y_i\mid x)$$
⇒ 链式法则是恒等变换、保留全部依赖 → 能表达任意多峰;独立假设丢掉 $y_{\lt i}$ → 只能单峰。PixelCNN 就用网络建模每个 $p(y_i\mid x,y_{\lt i})$。
像素独立模型把整张图拆成许多小问题:每个像素只看低清输入 $x$,不看邻居。
$$\log p(y\mid x)=\sum_{i=1}^{3M}\log p(y_i\mid x)$$
符号:$y$ 整张高清图,$y_i$ 第 $i$ 个标量像素,$x$ 低清输入,$3M$=$M$ 个像素 × RGB 3 通道。独立假设把联合概率写成连乘 $\prod_i p(y_i\mid x)$,取 log 后变成求和。
核心问题:每个像素各自投票,没人负责让边缘、鼻梁、阴影对齐。
独立像素模型的直觉
高斯 / L2 回归
固定方差时,最大似然等价于最小化 MSE,多种可能会被压成均值。
$$\log p(y_i\mid x)=-\tfrac{1}{2\sigma^2}\lVert y_i-C_i(x)\rVert_2^2 + \text{const}$$
$C_i(x)$ 网络预测的第 $i$ 像素中心值(均值),$\sigma^2$ 固定方差,$\lVert\cdot\rVert_2^2$ L2 平方误差,const 与 $y_i$ 无关。⇒ 最大化它 = 最小化 MSE,多个答案被压成平均值。
多项式 / 交叉熵
单点 softmax 能表达多峰,但不知道邻近像素选择了哪条结构线。
$$p(y_i{=}k\mid x)=\frac{\exp\{C_{ik}(x)\}}{\sum_{v}\exp\{C_{iv}(x)\}}$$
$k$ 某个离散灰度等级(0–255 共 256 类),$C_{ik}(x)$ 网络给第 $i$ 像素第 $k$ 类打的分数(logit),分母对所有类别 $v$ 求和做归一化。⇒ softmax 把分数变概率;单像素能多峰,但仍不看邻居。
把一个 MNIST 数字随机放到左上或右下角(各 50%)。数据集中从不同时出现两个数字 —— 这就是“两个分立的合理答案”。
① L2 回归(高斯 / MSE)
每个像素各自回归一个灰度值、最小化均方误差,本质是学“条件均值”。把“放左上”和“放右下”两种答案一平均,两个角都浮出半透明数字。
② 交叉熵(softmax 分类)
把每个像素灰度当成 256 类、各自做 softmax 分类。单个像素能表达多峰,但像素之间互不商量,仍会在两个角各放一个淡淡的数字。
↑ 两者都假设像素独立 → 产生训练集里根本不存在的“鬼影”。
PixelCNN(建模像素依赖)
逐像素自回归,后画的像素会参考先画的;于是随机但互斥地只把数字填进某一个角,和真实数据一致。
Figure 2 · MNIST 角落 · 数据构造(上)与各模型样本(下)

自回归图像模型的直觉
关键转变:像素不再各自投票,而是一个接一个、互相参考地学“下一个像素的概率分布”。
为什么叫自回归
先生成前面的像素,再把它们作为条件预测下一个像素。
为什么不再糊
每一步输出概率而非唯一数值,且参考已画像素;不同采样路径得到不同但协调一致的高清结果。
和超分的关系
原始 PixelCNN 是图像先验;本文把低清图 x 加进条件里,变成条件生成。
插值 / 先验 / patch
bicubic · sparsity / GMM · patch dictionary
速度快、可解释;但高频细节依赖手工假设或近邻检索。
CNN 回归
SRCNN · VDSR · SRResNet
pSNR / SSIM 持续提升;但 MSE 倾向学习“平均脸”。
感知 / GAN
perceptual loss · adversarial loss
感知损失是有效改进;GAN 更锐利但不稳,且难给概率解释。
自回归生成
PixelRNN · PixelCNN
能用 likelihood 覆盖多种样本;关键是接入低清条件 x。
本文定位:保留 CNN 条件信息 + PixelCNN 像素先验
p(y_i | x, y_<i) · 把高倍超分改成可采样的条件分布
研究缺口:条件分布
PART 02 / 04
方法
条件网络 + 先验网络 · 一个看全局、一个管细节,logits 相加
逐像素生成高清图 · 按行从左到右、自上而下
第 0 / 144 像素
当前像素
已画区 = 先验输入 y<i
未画
低清输入 x → Aᵢ(x)
每一步都给当前像素一个全局结构提示。
每一步都给当前像素一个全局结构提示。
x 正在参与每一步
当前像素的概率分布 p(yᵢ | x, y_<i)
蓝线 Aᵢ(x):低清图提示这里大致该多亮;青线 Bᵢ(y_<i):已画区提示怎样接得自然。两组 logits 相加再 softmax,按柱高抽一档填入红框。
x 不是摆设:它像草图,锁住脸的位置与明暗轮廓;先验网络再沿着已画部分补连贯细节。关掉 x 重跑,结果会失去全局结构并逐渐漂移。
链式法则是恒等式(对任意分布都成立),不是模型假设:
$$\log p(y\mid x)=\sum_{i=1}^{M}\log p(y_i\mid x,\,y_{\lt i})$$
模型的自由度只有两处:① 生成顺序;② 怎么建模每个条件 $p(y_i\mid x,y_{\lt i})$。PixelCNN 给出一种具体选择。
生成单位:$y_i$ 是一个 sub-pixel
$y_i$ 是单个颜色通道的值,$y_i\in\{0,\dots,255\}$(256 个候选)。不是一次预测完整 RGB 像素,而是逐通道、逐 256 类地预测。
顺序:光栅 + R→G→B
$i$ 先按光栅扫描遍历空间位置,每个像素内 R、G、B 三通道也依次生成。32×32 彩图共 $M=32\times32\times3=3072$ 个 sub-pixel。
为什么能并行训练又"不偷看未来":masked convolution
网络不会直接说「像素值是 128 的概率 70%」:它先给每个候选打分(logits),softmax 再把分数换算成概率,最后从概率里决策(采样或贪心)一个值。
三个候选颜色的小例子:logits 相加 → softmax
| 候选颜色 → | 暗 |
中 |
亮 |
|---|---|---|---|
| 条件网络 $A_i(x)$ | −1 | 2 | 1 |
| 先验网络 $B_i(y_{\lt i})$ | 1 | 1 | −1 |
| 相加 logits $A_i+B_i$ | 0 | 3 | 0 |
| softmax 概率 | 4.5% | 90.9% | 4.5% |
本质 · 只有「分数差」决定概率:$p_k/p_j=e^{z_k-z_j}$,所以给所有 logits 同时 +10([0,3,0]→[10,13,10])概率完全不变;softmax 后才落在 0–1、和为 1。名字源于二分类的对数优势 $\log\frac{p}{1-p}$。
三步:打分 → 概率 → 决策
① logits:softmax 前、用来比较各候选的未归一化相对分数(log 域),可正可负、不是概率、不和为 1。
② softmax:先 exp 再归一化,把分数变成和为 1 的概率。
③ 决策:从概率分布里采样一个颜色值;也可贪心取概率最大的值(论文两者都讨论)。
② softmax:先 exp 再归一化,把分数变成和为 1 的概率。
③ 决策:从概率分布里采样一个颜色值;也可贪心取概率最大的值(论文两者都讨论)。
为什么两支网络的 logits 能相加
① 结构上:$A_i(x)$ 与 $B_i(y_{\lt i})$ 都是对同一组 256 个候选、按相同顺序输出的 256 维 logits —— 所以能逐项相加(并非任意两个网络都能加)。
$$p_k=\frac{e^{A_k+B_k}}{\sum_j e^{A_j+B_j}}=\frac{e^{A_k}\,e^{B_k}}{\sum_j e^{A_j}\,e^{B_j}}$$
② 直觉上:$\mathrm{softmax}(A+B)\propto e^{A}\odot e^{B}$($\odot$=同一类别逐项相乘,非点积)—— 等于合并两边证据:两支同时看好的候选概率才高。
注(严谨):两支网络联合训练,各自输出不一定是分别校准好的独立概率。
论文 Figure 3 · 后期融合架构(含自回归反馈)
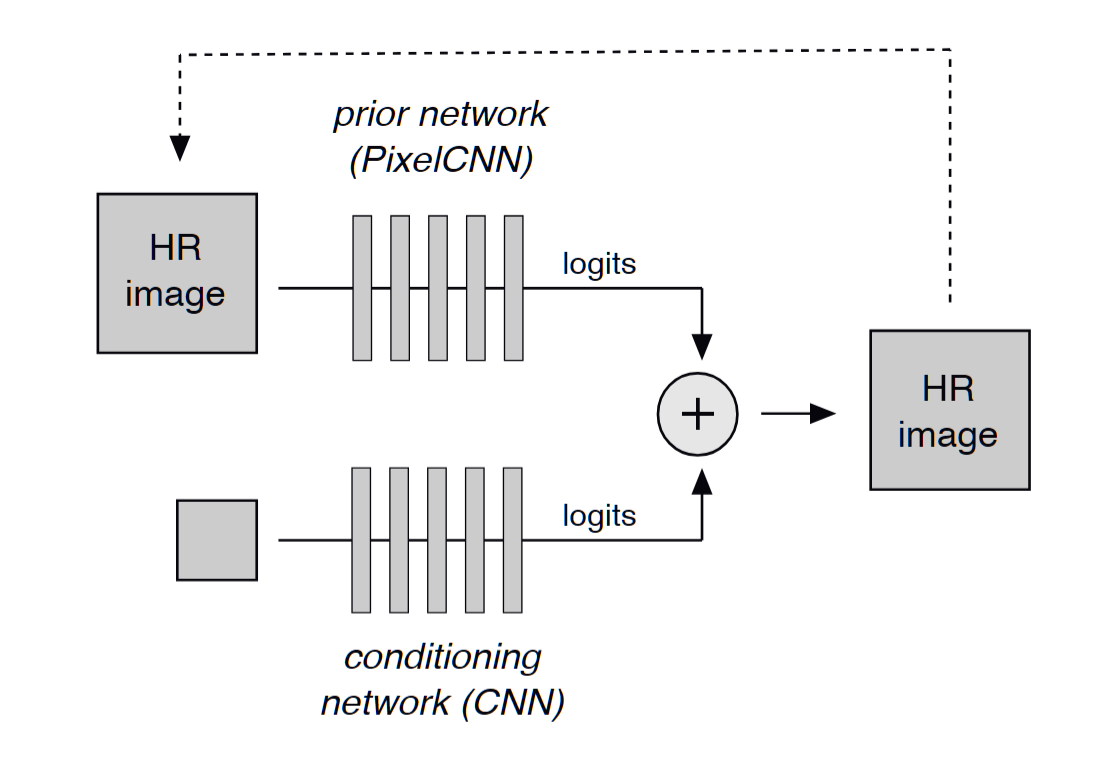
先验网络看 HR 前缀、条件网络看 LR,各出 logits → ⊕ → 采样新像素。虚线=自回归反馈:已采样的 HR 像素回流给先验网络,成为下一步的 y_<i。
① 条件网络 · 看低清 $x$(SRResNet 风格)
$x$ → 18–30 个 ResNet 块 → 转置卷积上采样到 32×32 → 1×1 卷积 → $A_i(x)\in\mathbb{R}^{256}$。管全局结构(朝向、轮廓)。
② 先验网络 · 看 HR 前缀 $y_{\lt i}$(Masked Gated PixelCNN)
$y_{\lt i}$ → 20 个 gated 块、每层 32 通道(masked 卷积)→ $B_i(y_{\lt i})\in\mathbb{R}^{256}$。管局部纹理(边缘、阴影延续)。
后期融合(late fusion)
$$p(y_i\mid x,y_{\lt i})=\mathrm{softmax}\!\big(A_i(x)+B_i(y_{\lt i})\big)$$
两支对同一组 256 候选各出 logits → 相加 → softmax(logits / softmax 见上一页)。
⚠ 主论文只给概要架构,完整层数/通道/超参见 supplementary material;输出是完整的 p(yᵢ | x, y_<i)(256 类),不是无条件的 p(yᵢ)。
训练 · teacher forcing
先验网络读的是真实高清前缀 $y^*_{\lt i}$(不是自己生成的)。配合 masked 卷积,一次并行算出全部 sub-pixel 的条件分布。
推理 · 采样
先验网络读的是模型自己采样出的前缀 $y_{\lt i}$;只能逐 sub-pixel 串行地生成。
条件网络为什么会被忽略:当前 HR 像素与之前 HR 像素的统计相关性,强过它与低清 $x$ 的相关性 → 先验网络天然强势,条件网络(看 $x$ 那支)梯度微弱、被淹没 → 结果不忠于输入。
对策:除了「合起来对」,再单独要求「只用条件网络也要对」——给它一份独立监督。
从最大似然到 $O_1$,再到 $O_2$
$\displaystyle \max_\theta\sum_D\log p_\theta(y^*\mid x)=\max_\theta\sum_D\sum_i\log p_\theta(y_i^*\mid x,y^*_{\lt i})\equiv O_1$
$\displaystyle O_2=O_1+\sum_{(x,y^*)\in D}\sum_i\log\mathrm{softmax}(A_i(x))_{y_i^*}$
$O_1$ 由条件最大似然直接得到;发现它会忽略 $x$ 后,作者人为加入辅助似然得到实际使用的复合目标 $O_2$。
先把公式读成人话:若网络在位置 $i$ 输出 256 类 logits $z$,把它给真实颜色 $y_i^*$的 log 概率记作
$\ell_i(z)=\log\mathrm{softmax}(z)_{y_i^*}=\mathbf{1}[y_i^*]^\top z-\mathrm{lse}(z)$。$\ell_i$ 越接近 0 越好;训练最大化所有位置的 $\ell_i$ 之和(代码若最小化损失,则 $L=-O$)。下文简写 $A_i=A_i(x)$、$B_i=B_i(y^*_{\lt i})$。
论文 Eq.(7) · 只考合并后的分布
$$O_1=\sum_{(x,y^*)\in D}\sum_{i=1}^{M}\ell_i(A_i+B_i)$$
展开 $\ell_i$ 就是论文原式。它只监督 $A_i+B_i$;先验项够强时,条件网络 $A_i$ 可以偷懒。
论文 Eq.(8) · Eq.(7) + 条件网络辅助目标
$$\begin{aligned}O_2&=O_1+\sum_{(x,y^*)\in D}\sum_{i=1}^{M}\ell_i(A_i)\\&=\sum_{(x,y^*)\in D}\sum_{i=1}^{M}\Big[\mathbf{1}[y_i^*]^\top(2A_i+B_i)-\mathrm{lse}(A_i+B_i)-\mathrm{lse}(A_i)\Big]\end{aligned}$$
额外的 $\ell_i(A_i)$ 使真实类别对应的 $A_i$ logit出现两次,所以展开后是 $2A_i+B_i$;这与论文原式完全等价。注意:生成时仍用 Eq.(6) 的 $\mathrm{softmax}(A_i+B_i)$,不是 $\mathrm{softmax}(2A_i+B_i)$。
采样过程 · 逐项串行
逐 sub-pixel 循环:采一个 → 喂回网络 → 采下一个;每个像素的 R、G、B 三通道也依次采样。
训练并行 · 推理串行
计算代价:32×32 采样约需 40 秒——朴素实现每生成一个 sub-pixel 都把整图重新卷积一遍;缓存中间状态可显著加速。训练侧用 masked 卷积可并行算出全部条件。
温度 τ 除在 logits 上再 softmax,控制分布尖锐度:
$$p_\tau(y_i\mid x,y_{\lt i})=\mathrm{softmax}\!\Big(\tfrac{A_i(x)+B_i(y_{\lt i})}{\tau}\Big)$$
同一组 logits,不同温度 → 不同尖锐度
怎么选 τ
τ → 0:趋近 greedy decoding(取概率最大那类),并非严格令 τ=0。
τ = 1.0:较自然,但常出现多余高频内容。
τ = 0.8–0.9:论文实验中质量通常最好。
τ = 1.0:较自然,但常出现多余高频内容。
τ = 0.8–0.9:论文实验中质量通常最好。
PART 03 / 04
实验与评估
画得像不像,让人来判断 · 传统指标与感知质量出现错位
① 数据与任务
CelebA
中心裁剪的名人人脸。
LSUN Bedrooms
卧室室内场景(验证不止适用人脸)。
Bicubic构造训练对
低清 $x$:8×8 → 高清 $y$:32×32(边长 ×4、像素 ×16)。
注:Bicubic只用于从高清生成低清输入,并非模型的超分方法。
② 训练与基线
训练配置(主文)
TensorFlow · 8 GPU · 同步 SGD · 端到端训练。
batch / 学习率 / 步数:主文未报告,见 supplementary。
batch / 学习率 / 步数:主文未报告,见 supplementary。
Nearest N. · 控制实验
训练集低清图按 L2 找最近邻 → 返回其高清版。检查模型是否只是记忆训练集。
ResNet L₂
架构≈条件网络;预测相对双三次结果的残差,用 MSE 训练。
GAN
损失 = 0.9×L1 一致性 + 0.1×对抗;仅人脸数据集比较。
③ 评估协议
相似度 · 越高越好
pSNR · SSIM · MS-SSIM。
一致性 · 越低越好
把生成高清图重新双三次降采样,与原低清 $x$ 求像素 MSE(平方 L2)。
人类评价 · 强制二选一
50% Fooled = 随机猜测 / 完全混淆基准。
⚠ 论文主文仅报告 TensorFlow、8 GPU 同步 SGD 等概要配置;batch size、学习率与训练步数需参考 supplementary material,本页不作推测。
Figure 1 · CelebA 人脸
Figure 4 · LSUN 卧室

模型合成出感知上可信的发丝、皮肤与材质,而非模糊的平均脸。
中列为模型采样,右列为真实图 — 两者气质相近但并不相同,正是多模态该有的样子。
同一建模框架可用于人脸与卧室;模型仍分别从对应数据集学习领域统计先验。
左列是同一个低清输入,右侧四列是 τ = 0.8 下的多次采样。
这正是目标
每次采样都给出一个清晰、可信但彼此不同的解 — Figure 5 至少表明模型能表达多个合理候选,而非只输出单一答案。
与 GAN 的区别
最大似然要求模型给所有训练样本分配概率,比对抗训练更不易遗漏模式(但并不保证绝不发生)。
注:温度 τ 只调分布的尖锐程度,并不直接控制发型、布局等语义。
Figure 5 · 左:低清输入 · 右四列:τ=0.8 的多次采样

Figure 6 · 各方法对比(图下 NLL = 最终模型对各候选图算的负对数似然,非各基线自身训练损失;越小=最终模型认为越可能)

收窄的结论:在最终模型的条件似然下,低 NLL 的单个候选不一定有更高的人类感知质量 —— bicubic / 贪心解码 NLL 最低却最模糊。NLL 来自 Eq.(7) 与 Eq.(8) 共享的主似然项;最终模型实际用 Eq.(8) 训练。
Table 1 (上) · CelebA 人脸
| CelebA | pSNR | SSIM | MS-SSIM | 一致性 | % Fooled |
|---|---|---|---|---|---|
| Bicubic | 28.92 | 0.84 | 0.76 | 0.006 | – |
| Nearest N. | 28.18 | 0.73 | 0.66 | 0.024 | – |
| ResNet L₂ | 29.16 | 0.90 | 0.90 | 0.004 | 4.0 |
| GAN | 28.19 | 0.72 | 0.67 | 0.029 | 8.5 |
| 本文 τ=1.0 | 29.09 | 0.84 | 0.86 | 0.008 | 11.0 |
| 本文 τ=0.9 | 29.08 | 0.84 | 0.85 | 0.008 | 10.4 |
| 本文 τ=0.8 | 29.08 | 0.84 | 0.86 | 0.008 | 10.2 |
Table 1 (下) · LSUN 卧室
| LSUN | pSNR | SSIM | MS-SSIM | 一致性 | % Fooled |
|---|---|---|---|---|---|
| Bicubic | 28.94 | 0.70 | 0.70 | 0.002 | – |
| Nearest N. | 28.15 | 0.49 | 0.45 | 0.040 | – |
| ResNet L₂ | 28.87 | 0.74 | 0.75 | 0.003 | 2.1 |
| 本文 τ=1.0 | 28.92 | 0.58 | 0.60 | 0.016 | 17.7 |
| 本文 τ=0.9 | 28.92 | 0.59 | 0.59 | 0.017 | 22.4 |
| 本文 τ=0.8 | 28.93 | 0.59 | 0.58 | 0.018 | 27.9 |
一致性 = 生成图重新双三次降采样后与低清 $x$ 的像素 MSE(平方 L2),越低越好;% Fooled 列的 ± 标准误见论文原表,本页为排版省略。
一致性:本文远好于 Nearest N.;CelebA 接近 Bicubic/ResNet,LSUN 虽高于二者但仍远低于 Nearest N. → 生成结果仍受低清 $x$ 约束,与 Eq.(8) 的设计动机一致。但论文未做 O₁/O₂ 消融,不能把结果直接归因于辅助项。 % Fooled:本文最高 → 传统 pSNR/SSIM 不等于感知质量。
评估协议
众包被试看到一张真图和一张模型输出,限时 1 秒回答“哪张是相机拍的”。模型越真实、被试越只能随机猜,fool rate 越趋近 50%(随机猜测基准 / 完全混淆)——50% 是基准,不是数学上限。
WORKERS
283
名众包工人
CHANCE
50%
随机猜测基准(完全混淆)
这页的重点不是“27.9% 已经完美”,而是 感知质量排序与 pSNR/SSIM 排序明显不同:传统指标高的回归模型,更难骗过人眼。
fool rate · 判断中把生成图认作真实照片的比例(按数据集分开)
虚线 50% = 随机猜测基准(完全混淆)。跨数据集不可直接比较。
27.9%
本文 · LSUN · τ=0.8
PART 04 / 04
总结
贡献 · 局限 · 留给后来者的思想遗产
质疑一 · 脑补 ≠ 取证
它是在合成细节,不是提取真相;绝不能用于身份识别 / 取证。
质疑二 · 结果仍是「玩具」
输出仅 32×32;与后续 GAN 路线相比,画质并不惊艳。
质疑三 · 对比不够强
GAN 基线较弱;还需要与 SRGAN 等强基线正面对比。
质疑四 · 缺少关键消融
论文称朴素目标 $O_1$ 会忽略低清条件,但未定量比较 $O_1$ vs. $O_2$ 的一致性、NLL 与感知质量,辅助项的实际贡献无法被单独确认。
价值在于把超分表述为概率多模态问题,并提醒我们反思传统指标。
贡献
- 把高倍超分刻画为多模态预测
- 用像素递归生成清晰、多样样本
- 用辅助损失防止条件被忽略
- 证明 pSNR/SSIM 与感知质量脱节
局限
- 采样慢 — 朴素实现一张 32×32 约 40 秒(二次复杂度)
- 分辨率仍很低(32×32),距实用尚远
- fool rate 最高 27.9%,离 50% 的完全混淆基准仍有距离
- 本质是「脳补」而非恢复 — 生成的是合理猜测,不能用于取证 / 身份识别
思想遗产
- 自回归 + 条件融合成为条件生成的通用范式
- “别在像素上求平均,对分布采样”影响后续生成模型
- 对评估指标的反思,呼应了 感知度量与人类评估的兴起
一句话总结:在这种高倍、欠定超分中,目标不是唯一“恢复”,而是合成可信的一种可能。
Dahl, Norouzi & Shlens · Pixel Recursive Super Resolution · ICCV 2017 · 谢谢聆听